
ARTICLE
Confused by data management? Don’t be. Here’s a way to think about it
There’s a world of difference between good and bad information. Ask any detective. And so, it follows that there’s good and bad oil and gas data, too.
Spoiler alert: those things everyone’s hoping will magically transform operating and financial performance—artificial intelligence (AI), machine learning (ML), and predictive analytics? They only work with good data!
This article is about the mission-critical process of identifying and extracting good data from an ocean of ones and zeros, and supplying consumers with exactly what they need, when they need it.
That process is called data management.
It’s a somewhat misleading term because it makes everything sound simple, in the way that “water supply” doesn’t do justice to the complexity of the infrastructure behind a faucet.
Water supply can be described as a sequence of stages: collection, cleansing, storage, and distribution.
Curate-Stream-Act
If that’s what happens under the sink, how should we visualize what happens behind the shiny analytics application on a cellphone? What functions, steps, plans, programs, and practices make up the data-management value chain?
Baker Hughes we think of data management as occurring across three principal stages: Curate, Stream, Act.
Curate describes processes that identify, clean, and catalogue potentially useful information. Like purifying swampy water to make it fit for consumption.
Stream describes the hardware, processes, and software that move curated data around the world to end-users, like the pipes that pump clean water from reservoirs to faucets.
Act describes the software and tools that help turn curated, streamed data into insights, insights into decisions, and decisions into business outcomes. That’s like everything water can be used for—cooking, bathing, or watering your lawn, for example.
Floating above each of these three stages is the meta-concept of data governance, which describes the systems, rules, and mechanisms that ensure data is well treated. Treating data well has two equally important benefits: first, that end users get useful information, and, second, that data-delivery processes navigate safely through mazes of legal and contractual data-related requirements.
Done right, treating data well can achieve game-changing outcomes. Indeed, getting the highest-quality data into cutting-edge analytics tools has become one of the most important things any upstream business can do.
A competitive differentiator
Why? Simply because computers can process information a lot faster than people can. They can, for instance, review decades-worth of historical data from offset wells fast enough to synchronize with field operations, providing real-time context to help planners refine decisions about operating parameters like well placement, tool selection, drilling trajectory, and rate of penetration.
Timely access to good intel can reduce drilling risk, lower emissions, improve safety, and increase or accelerate production. Eventually, when combined with automated well-site equipment, advanced AI and ML algorithms will be able to safely run some operating processes with minimal human oversight.
Deciding whether to place data and computing power at the center of your business is like wondering whether to manage the payroll with a quill and handwritten ledger or a state-of-the-art accounting application. Good data has become almost as critical to efficient, profitable oil and gas production as the commodities themselves.
But getting computers to do the heavy lifting reliably and consistently isn’t straightforward. The accumulation of historical data from decades of operations plus continuous inflows of new data from tens of thousands of well-site sensors is mind-bogglingly big. Not only that: data engineers attempting to bring order to raw data must typically grapple with varying formats, codes, and standards, and reconcile information scattered across enterprise systems, homegrown databases, government websites, daily drilling reports, and even offline folders on individual computers.
Skills, capabilities, and change management
To pull it off, you need to nurture the right blend of skills. You can’t only hire data engineers and scientists to do the work. They’ll build amazing dashboards, design smart applications, and write elegant algorithms. But at every stage of the data-management value chain, they must work closely with oil and gas domain experts to ensure information is meaningful to operations.
You need the right corporate culture, too. Data now underpins and enables value-creating decisions in every area of oilfield operations, from well planning to drilling and from production to remote operations. That means that everyone encounters data all the time, even if they’re not in a technical data role. From technical support to customer-service teams, right up to the CEO, everyone needs to see themselves as a data steward. That means taking care to enter data fully and accurately, scanning for errors and reporting them, remembering the period at the end of a line of code, and filling out the right fields in a report.
So, in addition to a robust data-management process, change-management capabilities are required to foster a data-driven mindset at all levels of the company. Even people hired to data roles, like coders, data analysts, and data-entry staff, may need help understanding how the enterprise strategy fits together.
But what should the strategy be? Let’s break down each of the stages.
Stage 1 - Curate
Curating enriches multiple sources of data of varying quality to produce “golden records”, the best and most complete version of the data that can be formed from the inputs available. To do that, data scientists and oil and gas domain experts must collaborate to master several sub-processes (see Figure 1).

-
Gather raw data from disparate sources
-
Clean the data by eliminating duplicates and consolidating similar information
-
Catalogue the data to indicate where data comes from, what it is, and where it’s being used
-
Identify and interpret analytically relevant data and events
-
Audit data to ensure it can be trusted
The first three steps, gathering, cleaning, and cataloguing, may be more challenging when it comes to historical data because there’s likely to be a large volume to process and because it’s more likely to be in a mess.
Managing new data from current operations should be easier if the right data-management systems are in place.
Stage 2 - Stream
The next stage, Stream, selects the information from curated databases that end users need and transmits it to them when they need it, in the format they require. Stream can be visualized in three interconnected sub-stages: Standardize, Secure, and Send.
Standardize means designing a technology stack that’s modular and interoperable. Modularity enables customers to add capacity as they need it, rather than trying to forecast requirements years ahead, which is likely to incur high up-front costs and may result in growth-limiting underestimates or costly overbudgeting and wasteful excess capacity.
Interoperability involves standardizing the output of a jumble of legacy databases by converting raw data into a standard format so it can be shared across systems with different languages, requirements, and protocols (see Figure 2).
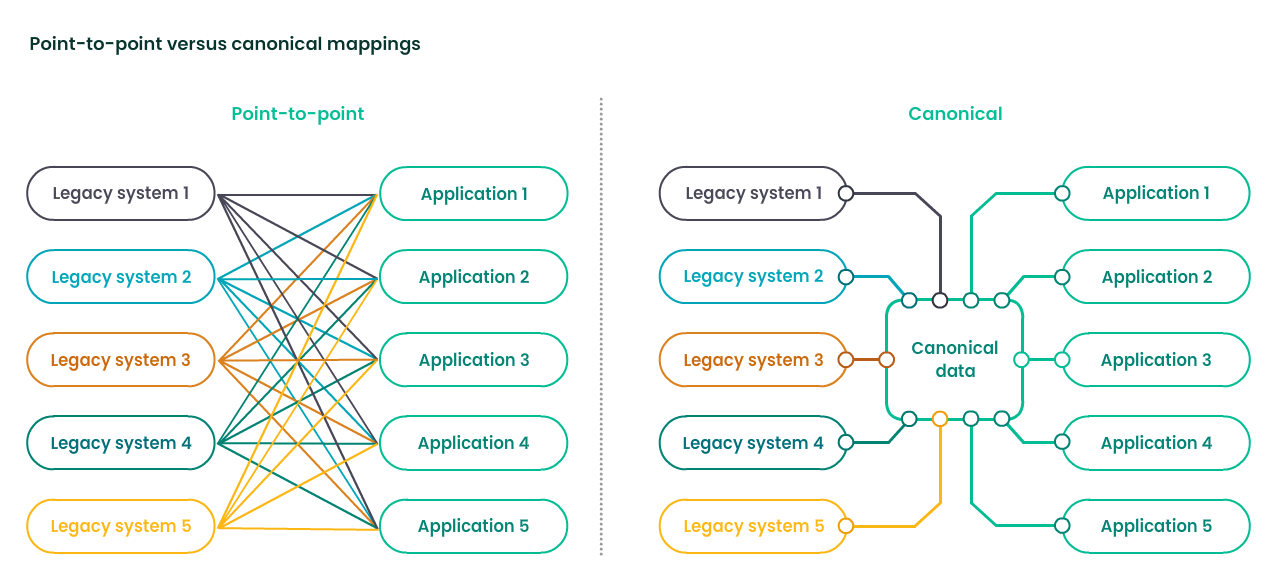
A canonical data model, sometimes called a common data model, radically simplifies connections between legacy systems and applications residing in the Act stage, removing the need for time-consuming point-to-point coding integrations and significantly reducing manual effort. In addition, directing the many third parties typically involved in rig-site operations to work to an industry standard such as WITSML or OSDU enables the seamless transmission of data from rig-site to data center, aligning operators, service companies, integrators, operators, partners, vendors, and government agencies.
Interoperability and modularity also give users the freedom to adopt the best solutions the marketplace has to offer in the future. At the input stage, therefore, a data system should be able to ingest data from any source. At the output stage, it should be flexible enough to accommodate any third-party application, so operators can add new data-analytics tools as and when they become available and don’t find themselves trapped in a single platform provider’s closed ecosystem of applications.
Secure describes data security, which means several things. For one, making sure data under your management can’t be accessed by unauthorized third parties or stolen as they are moved from point to point—and that data are protected against cyber-attacks. It also ensures the right people can access the data. Robust security standards are also needed for compliance with legal and contractual requirements, a core part of data governance.
Finally, Send. Like a network of water pipes, data streaming requires infrastructure to connect wells, rigs, and other upstream facilities with data centers. Everything from hardware like routers, servers, and other networking components to operating systems, software programs, data storage centers, wires, satellites, and wireless towers.
It’s a lot to build from scratch. Fortunately, third parties can provide the necessary ICT infrastructure in the form of à la carte cloud-streaming solutions.
Stage 3 - Act
This is the stage where we put the data to use, using AI and ML to operationalize it with context, insights, and productivity-enhancing workflows. Analytics have two possible end points: converting data into value by enabling either a better, faster decision or better, faster action. If neither outcome is achieved, the analytics aren’t working.
Analytics that drive decision-making can be conceptualized in four sub-stages: describe, predict, prescribe, and automate (see Figure 3).

Descriptive analytics involves the analysis of historical data to identify trends and patterns in past events. Understanding what happened in the past provides insights that can improve future performance.
Predictive analytics goes a step further by applying ML algorithms to historical data to make inferences and predictions. It fills in gaps with best possible guesses about what is likely to happen in the future.
Prescriptive analytics builds on descriptive and predictive analysis to recommend actions.
Over time, as those recommendations become more accurate and reliable, prescriptive analytics opens the way to full closed-loop automation, remote operations, and safe unmanned well-site operations.
When integrated with well designed, user-friendly software applications, the Act stage can deliver several other performance improvements, streamlining workflows, reconnecting siloed operations, saving time, fostering collaboration across disciplines and geographies, and generating high-definition visualizations at the click of a mouse. The list goes on.
Act doesn’t only promise to revolutionize well-site operations. Actionable data-driven insights can transform anything in a company’s value chain that generates a large quantity of data, from accounting to logistics. For example, data-driven insights into when field equipment is likely to need replacing enables operators to ensure that the right parts are manufactured and made available to the right field in good time, streamlining supply chains.
Actionable data-driven insights can transform anything in a company’s value chain that generates a large quantity of data, from accounting to logistics.
Yet no matter how well an Act-stage software application is coded and designed, and no matter how smart its algorithms, it won’t deliver its performance-enhancing promise if the data hasn’t been treated well further upstream. That’s why the back-end processes of data management, while less glamorous than the gleaming dashboard at the front end, are so critical to operating success. It’s why that’s where some of your first investment dollars should go.
Let’s get started
So, that’s it. A recipe for data management that can help ensure data is treated well, that actions and decisions become faster and better, and that capital investment is kept as lean as possible.
But success doesn't just depend on money and business processes: it’s about people, too.
Efforts to implement a robust data-management system must be complemented by structured education, training, and other change-management initiatives. They must create the right blend of capabilities, too, combining oil and gas expertise with data-science knowhow to bring context, insights, and domain discipline to the data.
It’s a challenging vision. But for an industry accustomed to pushing technological boundaries, it’s achievable.
Wondering how the OFSE Digital team at Baker Hughes can support your upstream data management operations? E-mail us at OFSDigital@BakerHughes.com to learn more.